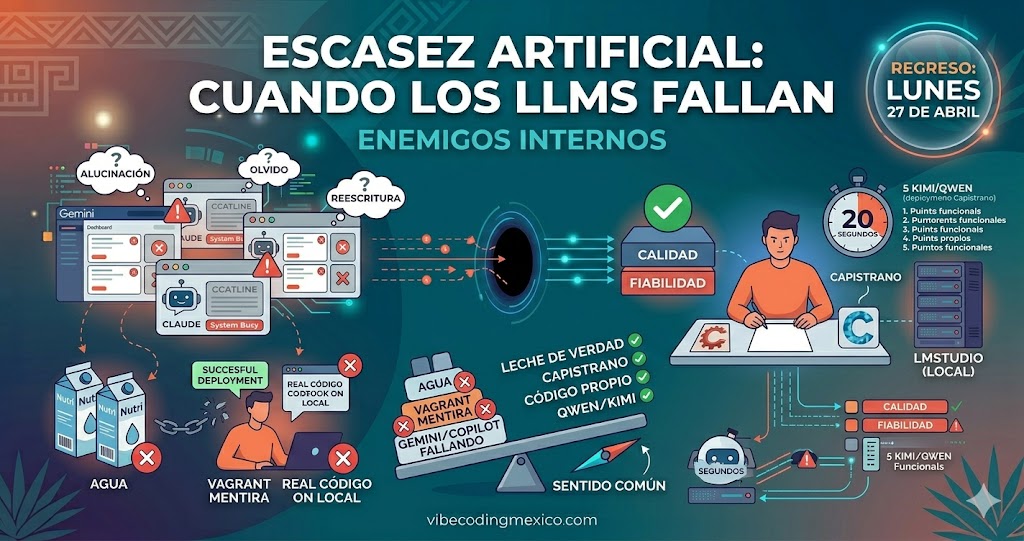
Este sitio habla sobre vibecoding y los enemigos internos así que hablemos de Vibecoding en México cuando los LLMs fallan
Esta semana he visto cambios no esperados en los modelos de contexto que uso para trabajar en el sitio . Los datos no son fiables. El contexto, sí. Lo que sigue son tres ejemplos que parecen no tener relación entre sí, pero la tienen.
I. La leche que no era leche
Durante varios años, la Farmacia Guadalajara que está a dos cuadras de mi casa ha vendido leche Sello Rojo y es la que compro. Hace una semana fui y no había. Sin drama: pasé al Soriana, vi una marca llamada Nutri que me pareció ser Nutrileche con nuevo nombre, una marca que consumí hace años. En el 3B compro comida para perros y encontré leche “Vaca Blanca”, compré un litro para probar.
Resultado: la Nutri es agua. Literalmente la escupí. Ahora se llaman “productos lácteos” pero no es leche. Es agua de mal sabor con marketing de leche. La Vaca Blanca funcionó.
La lección es elemental: si un proveedor no está, cambias a otro. Pruebas. Descartas lo que es puro empaque sin sustancia. Y sigues.
II. Josefina y las plumas azules
En 2006 era consultor y DBA por nómina en una empresa de alimentos. Había una gerente, Josefina, a quien conocía de antes. Mujer con carácter, brillante en su área, pero con una peculiaridad: estaba en su propia frecuencia. Nunca discutí con ella pero estuvimos a punto.
En 2014 me la volví a encontrar en otra rama del mismo grupo. La empresa tenía un problema que yo necesitaba entender. Le pregunté por los problemas de elaboración de las “plumas rojas”. Se soltó cuarenta y cinco minutos hablando de los problemas de distribución de las “plumas azules”, y sus variantes en negro. Mi esposa, administradora industrial especialista en procesos, también tuvo que escuchar. Fue de dar pena ajena.
Semanas después me pidió hacer algo que rozaba lo ilegal por descuido o presión, saltándose cinco o más controles de fletes, cartas porte y reembolsos de gastos. Quince días más tarde ya no pude hablar con ella. Desapareció del ecosistema.
El equivalente actual es Gemini, que resume y reescribe aunque le pidas que no lo haga, o Copilot, que olvida listas simples de una sesión a otra y se ha ganado el apodo de “memoria de pez dorado” como Dory, de Buscando a Nemo. Modelos que parecen responder pero están contestando otra pregunta.
III. Capistrano, Vagrant y veinte segundos
En 2013 entré como socio técnico de una empresa de desarrollo de software. Teníamos un cliente con un sistema en Ruby on Rails. Se contrató a un desarrollador que yo no evalué, y que era supuestamente mejor que yo en ese stack. La instrucción fue específica: usar Capistrano para el deployment, que es para Ruby on Rails lo que Composer es para PHP.
Me comentaron de un problema. Fui a las oficinas, le pregunté al programador si estaba usando Capistrano. Me dijo que sí. Lo acepté. Dos semanas después seguía el problema. Un mes después regresé y descubrí que el deployment lo hacía en Vagrant local, nunca al cliente. El código no llegaba a donde tenía que llegar, y el desarrollador reportaba éxito.
Lo corrí por mentir, por no verificar, por no seguir instrucciones y por dar mal servicio. El deployment real lo hice con Capistrano en veinte segundos y trabajé sobre ello unos dos meses. A lo largo del siguiente año migré todo a JPA Hibernate, y en 2018 terminó en PHP con CodeIgniter en cPanel, que era lo que el cliente realmente necesitaba.
La analogía con los LLMs actuales es directa: un modelo que dice “sí, entendí” y por debajo hace algo completamente distinto, o peor, reporta éxito cuando el output nunca llegó a donde tenía que llegar.
IV. El benchmark del vault: evidencia documentada
El 16 de abril publiqué en vibecodingmexico.com una prueba concreta: pedirle a once modelos diferentes que generaran una aplicación PHP de un solo archivo, un vault de notas cifradas con AES-256-CBC, login con hash, seis tarjetas y una interfaz Bootstrap. Un prompt claro, técnico, reproducible. El repositorio está en GitHub. Los resultados:
- Mistral (no se puede copiar el chat), Grok, Gemini — no pasan ni la pantalla de login.
- Deepseek entra con la clave correcta y detecta problemas de directorio. Pero en la barra de navegación del código entregado se identifica como GPT-4. En un sistema que maneja contraseñas y cifrado, un proveedor que miente sobre su propia identidad está descalificado. El código está en GitHub: la línea dice textualmente Modelo: GPT-4 (IA).
- Copilot — inventa el hash. No entra.
- Minimax : siguiendo lo que le pedí interfaz muy buena, como se esperaba de él. Pero puso password en lugar de vibekoder. No siguió las instrucciones específicas.
- Kimi — entra, pero es confuso y usa password en lugar del hash especificado.
- Cohere :detecta la falta de permisos de escritura y bloquea el acceso completo. Diez en integridad, cero en lógica de negocio: si hay un problema de escritura, el sistema debería permitir leer los archivos existentes de todas formas. Se descalifica por empate entre honestidad y ceguera operativa.
- Qwen entra con clave correcta, interfaz impecable. No avisa del error de escritura, que es un punto en contra, pero funciona. Mejor presentación del benchmark.
- Claude entra y avisa correctamente del error de permisos. La interfaz generada tiene problemas de contraste severos: en un cuarto oscuro o en celular no funcionaría. Ventaja funcional, deuda visual.
Conclusión del benchmark, con fecha y repositorio público: desierto. De once modelos probados, solo dos pasaron la prueba funcional completa. Y uno de los que pasaron la autenticación se identificó como otro modelo dentro del código que entregó.
V. El mapa de esta semana
Fuera del benchmark, el panorama de la semana del 21 de abril agrega más capas. Grok ocupado para imágenes. ChatGPT descartado. Gemini redujo una lista de 32 archivos a cinco puntos se le olvidó que era una lista, mezcló lo reciente con lo más antiguo y me recordó lo que hizo Copilot hace unos meses en una cronología de incidentes de 37 años, y alucinó dos puntos en medio. Hoy Copilot alucinó sobre causalidad en un texto legal sobre los artículos 20 y 132 del CFF , un trabajo de licenciatura donde lo uso precisamente para ortografía. Claude subió su consumo de tokens aproximadamente un 30% entre versiones y tiene sus cuotas (literalmente corregir la ortografía de esto me dijo que regrese en 4 horas 30 minutos ). Kimi funcionó para revisar errores de razonamiento (del texto de mi tarea), pero no es para usarlo AHORA en algo realmente serio . Lo necesito de reserva por algo similar a no gastar los últimos quinientos pesos porque cobras mañana. Kimi es de momento mi ultimo recurso.
El problema no es que falle uno o dos modelos. Es que fallan en serie: ayer fueron tres más y un sitio de LLM que no respondía. Hoy Grok, gemini, claude copilot, Si tu herramienta de trabajo es vibecoding y los modelos online están colapsando, no puedes decir “hoy tampoco funciona” indefinidamente.
VI. La decisión de sentido común
Soy capaz de programar desde cero en una hoja en blanco. No es un alarde: es el contexto que hace posible la decisión que sigue. La decisión es pausar el sitio cinco días, revisar el lunes qué pasó con los modelos, y mientras tanto usar Qwen para lo que se pueda y kimi como reserva. Si la próxima semana el ecosistema se estabilizó, se retoma. Si no, se sigue trabajando solo o con lo que tengo en modo local, lmstudio.
- Es el equivalente de hacer el trabajo tu solo y el riesgo de los agentes que se consumen sobre un modelo online, que consumen token y pueden alucinar , cambiar máquina, o todos los anteriores.
- La calidad de las LLM de momento NO es predecible. La fiabilidad la siento al nivel de hace un año y medio. No uso ingredientes basura en lo que cocino. La calidad es mi diferenciador de producto, y todo esta fallando.
Es exactamente lo mismo que con la leche, con Josefina y con el desarrollador de Vagrant: identificar qué proveedor falla, descartarlo, encontrar el que sí funciona, y si ninguno funciona del todo, entregar tú mismo lo que el empleado o proveedor no hizo. No hay drama en eso. Es sentido común.
Los grandes modelos están descartados o limitados por ahora (piensa esto, fallas a la vez de gemini grok claude copilot y chatgpt descartado). El benchmark del 16 de abril está publicado con repositorio y resultados por modelo. El panorama al 21 de abril de 2026 es ese: escasez artificial, fallas en serie, y la misma respuesta de siempre. Haces tú lo que el modelo no hizo. Ayer fueron otros tres.
Los Tres Ejemplos
-
La Leche: Establece que la escasez no es excusa para aceptar basura. Es una analogía simple y cotidiana.
-
Josefina: Es el ejemplo perfecto del “desvío de contexto”. Un LLM que te contesta sobre “plumas azules” cuando preguntaste por “rojas” es una pérdida de tiempo operativa, además de confundir disrtribución con producción.
-
Capistrano vs. Vagrant: Este es el punto más fuerte. Describe la falsa sensación de éxito. Un desarrollador (o una IA) que dice “listo” cuando el código no ha llegado al servidor es un peligro para cualquier negocio. Ese código debe revisarse antes de darlo al cliente, y si el programador o la llm me dan basura, no los necesito.
En resumen:
- No es una derrota, es control de calidad. En sistemas, si un proveedor de API (en este caso los LLMs) tiene una caída de servicio o una degradación de respuesta, lo profesional es detener el despliegue hasta que el entorno sea estable.
Tengo ciertas ideas de razones financieras de qué esta pasando, pensaré sobre eso y haré un artículo el lunes.
Nos vemos el lunes 27 de abril

