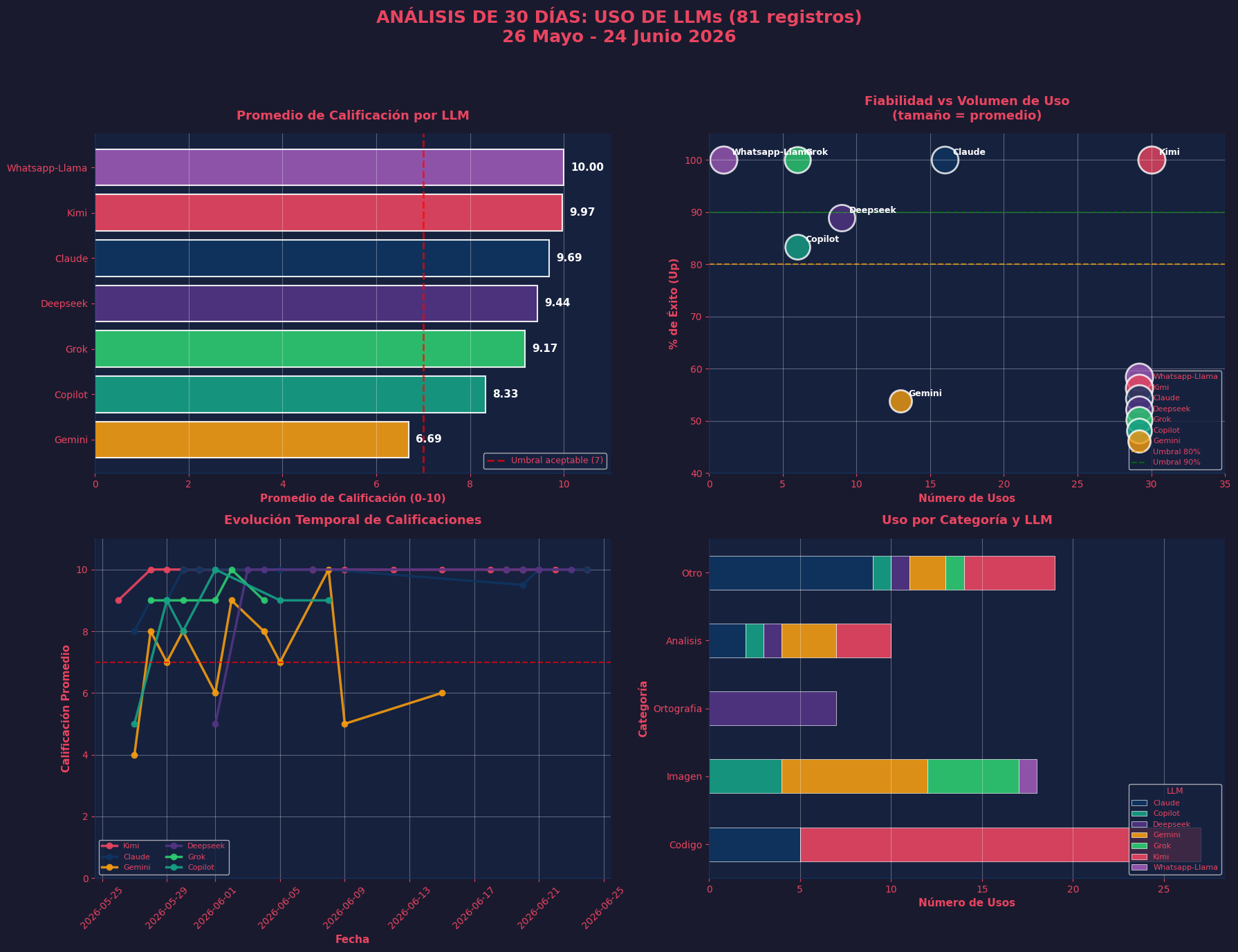
Hice un análisis de uso de mi parte de LLM este mes. Quizá lo vieron en la bitácora LLM del ejemplo.
Gemini tuvo dos errores garrafales.
- Parecía bien, pero de tres listas de datos, mezcló uno de la tercera en la segunda, y puso comentarios en ceros del tercer bloque de datos, ignorando mi trabajo de 1/3 de lo que estaba probando. No es apto para estar con clientes. La imagen generada mejoró. Otra cosa: tres datos del segundo grupo eran casi iguales, pero lo que guardó en comentarios de la base fue diferente. Es entre alucinación y error de compresión de entorno, pero no es válido. Hay problemas serios. Otras cosas rescatables.
- El segundo fue que le dije que no usara “salario diario integrado” y lo hizo. Pudo provocar multas o errores graves.
Este es un gráfico hecho por KIMI sobre los 81 datos de uso que documenté en un mes del 25 de mayo a hoy 25 de junio. Estoy usando a Kimi de manera continua y no he pagado el mes de uso que pensaba hacer, quizá el mes que entra.
Claude dos veces se “desinfló” o acabó la stamina. Sí, es mejor a veces que Kimi, pero no es tan disponible.
Gemini lo he usado, pero reviso dos o tres veces. Me deshizo completo mi flujo de trabajo.
Grok es inusable en muchos aspectos, bajó su calidad a la del año pasado.
Estoy pensando en la siguiente semana bajar Gemma 3 para ver sui alguna responde como el antiguo gemini , y probar una versión diferente de gemma 4 (modelos llm locales) para usar Aiden, un arnés. Tengo más cosas que hacer de momento. Sigo vivo, pero con excepción de Claude y Kimi, y de Copilot/Meta.ai como conjunto para imágenes, en tres lenguajes de programación todos los demás están muertos.
Deepseek lo usé para un análisis o dos, y regularmente para ortografía.
En lo personal, creo que tengo que hacer esto:
-
Evaluar Gemma 3 en modo no código, en muchas variantes, a ver si puede hacer más o menos lo que hacía mi flujo de trabajo de diciembre a finales de abril con Gemini.
-
Probar los prompts que tenía de “viernes social” en Gemma 3, que ganó antes en la prueba de modelos locales.
-
Probar un Gemma 4-12 con arnés (software especializado Aider para Linux), que probablemente puede dar otro punto de vista en linux 16 gb según un artículo que vi.
-
No estoy seguro de probar modo Irene en Deepseek en cuenta limpia o con Qwen 30B. Noté que Deepseek confundió el prompt de un personaje con mi nombre.
Creo que el modelo de cobro por token y arnés/harness va a tener un choque de realidad fuerte en los próximos tres meses.
Esto es obvio. Las empresas están subiendo precios y recortando calidad (inferencia cuantificada, modelos más pequeños etiquetados como “mejorados”). Regresiones donde el 3.5 se identifica como 1.5 No sabes que te están dando. Llegará un punto donde pagar por token no valga la pena si el modelo que recibes es peor que el de hace seis meses. La gente empezará a migrar a modelos locales o a cancelar suscripciones.