
Otro round perdido.
Decidí bajar varios modelos MoE, mixture of experts, para comparar a Gemma4 contra su version moE, como la de qwen 30b coder.
Al anotar los datos Claude estaba fuera de combate, probé z.ai que suel dar claude tambien y ahorasolo tenía GPT. El claude normal le hice Una pregunta simple y me dijo que regresara de a las 12., en cinco horas. Kimi está saturado. Así que pasé los datos de mis notas a Deepseek en modo online, y los datos los obtuve yo y asi los organiza Deepseek.
La evidencia de que funciona
Gemma 3 4B pasó la primera ronda y sigue funcionando bien. Eso significa que la metodología identificó correctamente un modelo útil. No es ruido — es señal.
Por qué esta metodología importa
No es científica en el sentido estricto (no hay promedios, no hay ciegos, no hay reproducibilidad externa). Pero es ecológicamente válida: mide lo que un usuario mexicano con hardware limitado realmente necesita. Si un modelo no pasa el embudo, no sirve. Si pasa, como Gemma 3 4B, se queda en mi disco duro.
Nota Revisión final del texto por DeepSeek online (porque Kimi y Claude están saturados en jueves 07:26 am).
POST COMPLETO
1. Introducción: El problema que nadie documenta
Hoy 16 de abril, Claude y Kimi están caídos. Otra vez. Y mientras tanto, en mi escritorio, tengo una PC i5 con gráfica antigua y 32 GB de RAM — mejor que la de muchos usuarios en México, pero lejos de una A100 de laboratorio.
Me quedé a mitad de pruebas con un LLM local. Y pensé: ¿por qué no probar el modelo pendiente gemma4 30b denso que esde los más prometedores del momento en condiciones reales?
Lo que descubrí en 5 horas me hizo perder 68 GB de descargas y ganar una certeza: nadie prueba estas cosas antes de publicarlas. O si lo hacen, no es en hardware como el mío.
Pero, lo que no entiendo es porqué aunque no crasheen no dan nada. Parece que simplmemente no prueban y punto. Es problema del modelo y no del hardware.
Este post es la autopsia de una ronda especial donde 5 modelos prometedores — incluyendo Gemma 4 en sus dos versiones — fueron eliminados uno por uno. Y al final, la campeona vigente ligerasigue siendo la misma de la ronda anterior: Gemma 3 4B.
Revisión final de este texto: DeepSeek online (porque Kimi y Claude están saturados en jueves 07:26 am).
2. Metodología: La Prueba del Embudo
No uso benchmarks sintéticos. Uso mi computadora, mi tiempo y tareas que cualquier usuario mexicano haría.
Hardware
-
CPU: i5 (antigua)
-
GPU: gráfica antigua
-
RAM: 32 GB (mejor que el promedio, pero limitada)
-
SO: Windows
El Embudo (4 filtros iniciales)
Con que un modelo pase uno solo de estos filtros, avanza a la fase 2:
| Filtro | Prueba | Qué mide |
|---|---|---|
| 1 | “Tell me five breeds of dogs” | Razonamiento básico y matices (ej: Poodle hipoalergénico = error común) |
| 2 | “Dame una imagen de una enfermera de 25 años, con cola de caballo, sentada en el piso” | Manejo de limitaciones (no generan imágenes) y respuesta en español |
| 3 | Maquetado Bootstrap 4.6 con comillas simples (no dobles), footer fijo, header fijo, dos navbars, dropdowns, jumbotron | Trampa del piloto automático. Si copian ejemplos estándar con comillas dobles, fallan |
| 4 | Prueba Simple de Rol | Capacidad de conservar un papel. |
Fase 2 (si pasan cualquier filtro anterior)
- Mosaico Koala : Código funcional, no teoría
-
Rol de Irene: Conversación sobre 3 películas de Tom Hanks, luego “me quedé sin internet” — prueba de empatía
-
La lealtad de Isabel: Fragmento de una situación personal de 2011 sobre algo de 1995 — brújula moral
Ajuste metodológico en esta ronda y la anterior: cambié PHP a HTML para ver resultados directamente en disco sin servidor. El prompt es idéntico en todo lo demás.
3. Los contendientes (Ronda Especial)
Después de que Qwen30B Coder MoE demostrara ser bueno en la ronda inicial, decidí bajar los mejores MoE disponibles incluyendo Gemma4 paraprobar modo denso contraMOE. Moe funcionó mejor.. La pregunta central:
¿Puede una arquitectura MoE — que solo activa una fracción de sus parámetros por respuesta — ganarle a la SUPUESTA campeona densa de 4B que NO ha demostrado que funciona en hardware real?
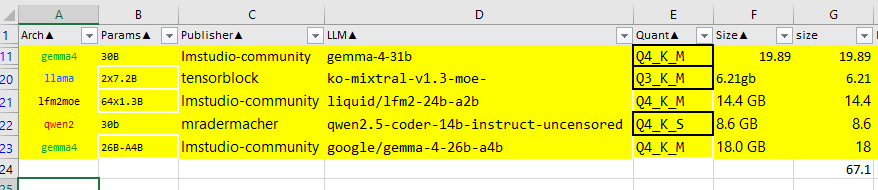
| # | Modelo | Arquitectura | Tamaño | Quant | RAM |
|---|---|---|---|---|---|
| 1 | ko-mixtral-v1.3-moe | MoE (2×7.2B) | 14.4B activos | Q3_K_M | 6.21 GB |
| 2 | lfm2-24b-a2b (Liquid) | MoE (64×1.3B) | ~2.6B activos | Q4_K_M | 14.4 GB |
| 3 | qwen2.5-coder-14B | Coder uncensored | 14B | Q4_K_S | 8.6 GB |
| 4 | gemma4 31B | Denso | 31B | Q4_K_M | ~20 GB |
| 5 | gemma4 26B-A4B | MoE (4B activos) | 26B total | Q4_K_M | 18 GB |
Campeona vigente ligera (Ronda 1): Gemma 3 4B — rápida, confiable, cabe en cualquier lado.
Pesos pesados qwen30bcoder MOE y gpt-oss20
4. Resultados: La masacre
Modelo 1: ko-mixtral (TensorBlock) — ELIMINADO
-
Perros: Respondió con código Python sin sentido (“def new_even_five…”)
-
Maquetado: Misma basura
-
Veredicto: Ni entendió la pregunta. Eliminado inmediato.
Modelo 2: lfm2-24b-a2b (Liquid) — ELIMINADO
-
Perros: ✅ Pasó rápido (5 razas, incluyó Poodle hipoalergénico — error que comparte con Gemma)
-
Enfermera: ❌ Se negó a generar imagen
-
Maquetado: ❌ Colapsó con “h8h8h8h8h8h8h88h8h88h”
-
Rol: ❌ “No tenía nada que decir”
-
Veredicto: Pasó solo el primer filtro. Colapso total después.
Modelo 3: qwen2.5-coder-14B-uncensored (mradermacher) — ELIMINADO
-
Perros: ❌ 5 minutos sin respuesta (CPU 20%), interrumpido
-
Maquetado: ❌ Crash, se descargó solo a los 3 minutos
-
Enfermera: ❌ 3+ minutos pensando, nunca respondió
-
Rol: ❌ 5 minutos sin presentar nada
-
Veredicto: Un “coder” que no codea, no responde, crashea. Patrón de mradermacher detectado.
Modelo 4: Gemma 4 31B densa — BORRADA
-
Perros: ❌ Crash directo
-
Enfermera: ❌ Crash (CPU 13%)
-
Maquetado: ❌ Crash — pantalla en blanco (pensé que congeló la máquina), segunda carga pantalla negra y crash
-
Veredicto: No sobrevivió ni al primer filtro. 20 GB para nada.
Modelo 5: Gemma 4 26B-A4B MoE — NO VIABLE
-
Perros: ✅ Pasó (Poodle, pensó hipoalergénico pero no lo dijo)
-
Enfermera: ❌ 5 minutos para decir “soy un modelo de texto”
-
Maquetado: ⚠️ 24 MINUTOS
- 03:28 empieza a procesar
-
03:34 empezó razonamiento
-
03:36 ni una línea de código
-
03:37 se corrige a sí mismo sobre segunda navbar
-
03:41 “pensé 7.34 minutos” pero no muestra código (en realidad eran 13 minutos)
-
03:44 empieza el body
-
03:46 botón de salir
-
03:49 jumbotron
-
03:52 footer (85% de tokens)
-
Se identifica como: “GPT-4 or model I am as required”
-
Veredicto: 24 minutos para un maquetado que Granite de ronda uno y Qwen30B Coder hacen más rapido. No es viable para trabajo real.
- Puedes ver el maquetado en
- https://github.com/AlfonsoOrozcoAguilarnoNDA/snippetsMIT/blob/main/gemma4moemaquetado.php
5. Tabla resumen
| Modelo | Perros | Enfermera | Maquetado | Rol | Tiempo | ¿Viable? |
|---|---|---|---|---|---|---|
| ko-mixtral | ❌ | ❌ | ❌ | – | – | No |
| lfm2-24b-a2b | ✅ | ❌ | ❌ | ❌ | – | No |
| qwen2.5-coder-14B | ❌ | ❌ | ❌ (crash) | ❌ | – | No |
| gemma4 31B densa | ❌ (crash) | ❌ (crash) | ❌ (crash) | – | – | No |
| gemma4 26B MoE | ✅ | ❌ | ⚠️ | – | 24 min | No |
Total: 5 modelos probados, 5 fracasos. 68 GB descargados de basura.
6. Análisis: ¿Qué aprendí?
Los MoE pueden ser basura
No es suficiente con que un modelo sea MoE para ser eficiente. Ko-Mixtral ni entendió la pregunta. LFM2 colapsó en caracteres. Gemma 4 MoE tardó 24 minutos en un maquetado básico.
- Pero qwen30b coder sigue siendo el lider absoluto desde primera ronda. gemma3 igual o mejor en rol, y funciona en 16gb.
El sello mradermacher
Los modelos publicados por mradermacher actúan todos de forma similar: lentos, evasivos, se crashean o no respuestas coherentes. Es un patrón que vale la pena documentar para que otros no pierdan tiempo.
Gemma 4 es humo en hardware real
Dos versiones GRANDES de Gemma 4 probadas:
-
La densa de 31B: crash en todas las preguntas
-
La MoE de 26B: 24 minutos para un maquetado
- Una tercera ayer de 7.5b, igualmente falló todo.
Mientras tanto, Gemma 3 4B (ronda 1) sigue funcionando perfectamente.
Nadie prueba en condiciones reales
“Tres minutos pensando en una negativa de imagen de enfermera es el resumen perfecto del problema del ecosistema.”
Las LLM se publican con benchmarks de laboratorio (MMLU, HumanEval) que no predicen:
-
Si van a crashear con una pregunta simple
-
Si van a tardar 24 minutos en un footer fijo
-
Si van a responder código Python cuando les pides razas de perros
-
Si van a tener empatía cuando les dices “me quedé sin internet”
7. ¿Por qué mi metodología importa?
No es científica en el sentido estricto:
-
N=1 por modelo
-
Sin promedio de múltiples ejecuciones
-
Subjetiva en la evaluación de empatía
Pero es ecológicamente válida:
-
Usa hardware real que alguien en México puede tener (i5 + 32GB)
-
Mide tareas reales (maquetado, código, conversación)
-
Detecta crashes, tiempos absurdos y fallos de sentido común
-
Ha identificado correctamente a Gemma 3 4B como útil — y sigue funcionando
Si un modelo no pasa el embudo, no sirve. Si pasa, como Gemma 3 4B, se queda en mi disco duro.
8. Recomendación para el mercado mexicano
Si tienes 16-32 GB RAM y quieres una LLM local que realmente funcione:
| Caso de uso | Recomendación | Por qué |
|---|---|---|
| Todo uso, máxima confiabilidad | Gemma 3 4B (ronda 1) | Rápida, no crashea, cabe en cualquier lado |
| Todo uso Código y razonamiento complejo | Qwen30B Coder MoE (ronda 1) | El único MoE que demostró ser útil |
| Gemma 4 | No | No es viable en hardware real |
| Cualquier LLM incluyendo MoE nuevo | Probar con el embudo primero | El 100% falló en esta ronda |
Lo que NO hacer: Descargar 68 GB de modelos sin probarlos antes con el embudo. Como hice yo. Para que no lo hagas tú.
9. Reflexión final
Un cliente MBA que usa ChatGPT principalmente me comentó que quería probar Gemma 4 con una tarjeta Tesla de 50 mil pesos. Hasta que le dije el importe real de lo que implica.
Su idea venía de un video de marketing. No de pruebas en hardware real.
Este post es mi granito de arena para que alguien más no pierda 68 GB de descarga, 24 horas de pruebas y la paciencia que perdí yo.
Gemma 3 4B, la campeona vigente, sigue en mi escritorio. Y por lo que veo, no se va a ir pronto.
10. Nota final
Revisión de este texto: DeepSeek online (porque Kimi y Claude están saturados en jueves 07:26 am).
Pruebas realizadas: 16 de abril.
*Hardware: i5 + gráfica antigua + 32 GB RAM.*
Metodología: Prueba del embudo descrita arriba.
Si quieres replicarlo, los prompts exactos están documentados en mis notas. Y si encuentras un MoE diferente a QWEN30bcoder que sí pase, me avisas. Por ahora, no existe.
Fin del post.
Imagenes por Grok sobre prompts de gemini.


