Otro mas de Domando la caja negra, donde muestro formas de trabajar con IA aplicadas a tu propio flujo de trabajo.
He comentado que recomiendo, al levantar un servidor desde cero, usar Debian. Sin embargo, por necesidades de la operación y de la vida, he usado muchísimas versiones de Linux. Actualmente uso tres para cosas de trabajo más o menos frecuentemente y, a veces, Ubuntu como mal necesario. Uso normalmente Debian, Rocky Linux y Arch Linux. Debo tener uno o dos servidores de AlmaLinux, pero no los uso tan seguido; actualizo cada 15 días y no he visto nuevas versiones. Son principalmente para cPanel.
Mentalmente tengo una idea de lo que voy a hacer cuando preparo un servidor. Una dama que va a comprar pollo puede prepararlo de muchas maneras si lo compra en el súper, pero si tú vas a Kentucky Fried Chicken, es receta secreta o crujiente. Llegar a pedir una Big Mac es un modelo mental incorrecto.
En lo personal, tengo servidores que no muevo, solo cuando me pagan o hay un problema o necesitan parche. Hay de varias versiones, pero en mis servidores normales de trabajo los tengo en dos categorías: los que están optimizados desde cero con Debian y unos que preparo para pull request. Déjame explicar qué es un pull request.
Pip, npm y Composer traen módulos cuando los ejecutamos, causando problemas de memoria a veces y dependencias que no queremos, pero tú lo inicias. Microsoft y su Windows son push request: lo hacen cuando les da la gana. Pull request significa que tú sabes cuándo actualizas, y push request que lo hacen casi sin darte cuenta.
En mi modelo mental, usas servidores de trabajo y archivos de dos maneras:
- El uso del programa genera base de datos y archivos en disco; hay que respaldar ambos. Por ejemplo, WordPress genera archivos en disco: se respaldan base de datos y archivos, no vuelves a reinstalar de cero WordPress cada vez. Este tipo de cosas, cuando no son cPanel, los suelo hacer en Debian.
- Algunos no graban en directorio, solo base de datos. Y si están bien hechos, no necesitan mantenimiento. Así que esos hago pull request cada cierto tiempo y respaldo la base de datos únicamente. Esto lo suelo hacer en Rocky Linux.
Modelo mental 1: Debian y Rocky Linux como ecosistemas diferentes
Hace unos días vimos un panel de Vultr, que tiene banderas del lugar donde está el servidor. Otra bandera es el sistema operativo que tiene. A veces estoy cansado, pero por default sé que si estoy trabajando en algo que usa Debian y paquetes apt, lo que tengo que respaldar son archivos y base de datos. Y subo cambios a mano o por un proceso push.
Pero si el servidor usa paquetes DNF, es Red Hat o ahora Rocky Linux, y ahí solo respaldo base de datos. La actualización es correr el update del terminal, y si hago cambios, tengo un mecanismo elegante que no usa Gitea Actions ni similares, y que me hace el “despliegue” de CI/CD con un solo paso. Es decir, uso una orden tipo https://dominio.com/despliegue.php, y trae solo de un repositorio de GitHub o Gitea los cambios. Inclusive uso como editor el de GitHub.
Estos proyectos son muy cómodos, ¿no crees?
Es posible hacerlo también en Debian Linux, con dos órdenes, pero mi modelo mental me lo prohíbe. Por si las dudas te he creado un nuevo manual que puedes descargar, de Rocky Linux 9 y su instalación, para este tipo de proyectos. Como Rocky Linux 9.0 es lo que tienen varios de mis clientes instalado porque está con LTS, te hago ese comentario: Rocky Linux 9 puede ser igual que el 10, las diferencias son mínimas.
Esta es mi guia Licencia MIT de instalar Rocky Linux con lo necesario para servidor Pull
https://github.com/AlfonsoOrozcoAguilarnoNDA/snippetsMIT/blob/main/instalar_LAMP_gitea_rocky9.md
Ahí mismo estan Guias de instalación de Debian13 y pronto una más de Arch Linux.
Necesito que entiendas esto, lector, para poder seguir con los otros temas.
La idea secundaria es que las salvaguardas de diferencias de Rocky Linux vs Debian te impiden meter un clavo donde va un tornillo. Visualmente y físicamente tienes salvaguardas y te mantienes al día en dos tecnologías.
Resumen:
Hay modos de jalar tu proyecto de un repositorio, sobre demanda, y que ya no tengas que hacer nada más que correr el actualizador cuando hay actualización o quieras hacerlo. No más interrupciones estilo Windows Update, ni que sea cuando le da la gana a los demás. Cuando hable de Rocky Linux y servidores pull, me refiero siempre a servidores que solo respaldo la base de datos. Eso es importante porque una reinstalación sin precaución te borra todos los archivos, y eso es muy malo si tienes datos. Así que, salvo que diga lo contrario, te hablaré de Rocky Linux cuando sea pull, y de Debian cuando sea configurado a mano, de manera artesanal, que respalda base de datos y archivos y YO SUBO LOS DATOS de manera diferente a repositorio público.
Así que para mí el primer modelo mental son servidores Debian y Rocky Linux, con paquetes de órdenes diferentes, que me obligan a no ejecutar el mismo script de otra clase por error.
El segundo modelo mental que uso lo explicaré así:
Modelo mental 2: Chunk
Si tu idea es correr 400 metros planos, primero empiezas con 100 y luego 200. Si lo dejas a la mitad no cuenta. Ahora vamos a suponer que, si por alguna razón decides que tienes que comprar 24 unidades USB de la misma marca, tu objetivo es parcialmente válido aunque no consigas todo en un solo paso. Si tu objetivo es, por ejemplo, comprar 24 USB de cierto modelo que venden solo en Office Depot, y en el primero encuentras cinco, ya solo necesitas 19 y esos USB son útiles por sí mismos.
No son piezas de un rompecabezas. Un rompecabezas solo funciona si están todas sus partes, así como no sirven de nada los primeros 200 metros de una carrera de 400 metros.
Tienes que empezar a pensar en términos de chunk: labores cortas, graduales, que en aproximaciones sucesivas hagan algo mayor. Es decir, como un modelo mental de producto mínimo viable y luego ir mejorando. Cuando juntas 5 más otras 9 ya tienes 14, y otras 10 y ya lo hiciste. Ahora bien, en la vida real lo que te van a decir es: “Compra… no sé… yo creo que unas 20 o 24…” No saben para qué, pero son útiles. Malo sería si te dijeran: “Compra 20 impresoras de credenciales de PVC para mañana y todas del mismo modelo.” Ahí sí compras todas juntas o acabas en basura y problemas de mantenimiento. Eso no es un chunk.
Por ejemplo:
- En https://vibecodingmexico.com/laboratorio-4-tickets-multiempresa/ Menciono como usar chunks para una prueba de grok en un sistema de Tickets.
- En https://vibecodingmexico.com/laboratorio-2-sistema-de-compras/ Explico como usar Kimi para un sistema, de compras.
El chunk es la unidad de diseño.
1. El Chunk como “Contenedor de Contexto”
-
La IA no tiene que adivinar: Sabe que el alcance son las ~400-600 líneas de ese archivo específico.
-
Densidad de atención: Toda la capacidad de procesamiento de Kimi o Grok se concentra en integrar el nuevo elemento del catálogo de proveedores, sin distraerse con el resto del sistema.. Si sale un nuevo campo le digo, lee el documento docx y rehaz el chunk 8, tengo un campo nuevo x.
2. Inyección de Datos Frescos (RAG Manual)
Cuando dices “en base al documento docx”, estás aplicando lo que en ingeniería se llama Retrieval-Augmented Generation (RAG), pero de forma artesanal y controlada. Le das la fuente de verdad (el nuevo catálogo) y la idea base (el chunk 8).
3. El flujo de trabajo quedaría así:
-
Identificación: “El cambio solo afecta al catálogo de proveedores” → Chunk 8.
-
Instrucción: “Kimi, toma este nuevo documento de requerimientos y actualiza el Chunk 8 que hicimos antes”.
-
Validación: Como el archivo es pequeño (menos de 1,000 líneas), puedes ver de un vistazo si la IA respetó la estructura anterior o si “alucinó” algo.
-
Despliegue (Pull): Subes el cambio al repo de Rocky Linux y haces el
pullal servidor. Listo.
¿A ver ? como estuvo ?
Programar con IA no es un evento único, es un ciclo.
-
No se trata de que la IA te haga el código y ya.
-
Se trata de cómo gestionas la evolución de ese código a lo largo del tiempo sin que se rompa.
Modelo Mental 3: algo real en 500 y 1000 líneas
Una de las características de trabajar en chunks es similar a los microservices. A mí me gusta trabajar con PHP y sistemas de pocos archivos porque puedo tener control de qué tienen, dónde están, y el número de líneas me da una señal importante. Si yo le doy a Gemini un código de 250 líneas para que suba más funcionalidades, no me debe regresar uno de 50 líneas, ¿verdad? A ojo sé que ya no es lo mismo.
Bueno, pues resulta que la versión gratuita de Claude maneja en modo web hasta 600 a 1000 líneas de entrada sin confundirse en el prompt. Por eso los proyectos maltir y dolgul (tickets y compras) los hicimos por chunk: si el archivo es menor de 1000 líneas probablemente no se equivoca.
Pero hay otra ventaja. A veces tienes cosas probadas y quieres resumirlas.
¿Cuál es mi salida estándar? 1200 líneas. Y si tengo 900 lo dejo como está. Ejemplo:
Le digo a Claude: “Aquí tienes estos tres archivos de 250 líneas, por favor condénsalos en un solo archivo y sepáralos en tabs.” Si cada uno es de 250 líneas, el resultado que espero es de 750 líneas. Por lo general te da unas 600 líneas. A veces 900, porque así es la vida.
Usando una idea de hace unos años, hace unos seis meses le pedí a Gemini que me hiciera un sistema de tiles o mosaicos de Windows 8 estilo Metro, que me permite ver sin problemas los archivos PHP existentes, solo que aquí además de lanzarlos, ver las líneas de código. Luego hice otra versión que me dice los archivos que no son PHP, para que pueda ver qué está pasando por el servidor. Eran dos archivos de 250 líneas. Ese lo uso mucho.
Pero además trato de estar consciente de si ese script usa base de datos o no. ¿Por qué?
Bueno, tener un montón de chunks que operan con base de datos es más útil que si los revuelven con los que no.
Tres cosas normales, que hemos visto aquí:
- Mi control de mosaicos: 250 líneas para tamaños de archivo.
- Control de favoritos: ~400 líneas.
- Control de dashboard de detenidos.
Tengo una solución de 420 líneas que me permite un control maravilloso de pendientes y no necesito nada más. Para mí tiene sentido, en mi modelo mental, un límite de 1000 líneas en cosas de IA, que a veces sube a 1200. Sin embargo, es porque uso modelos gratuitos y pruebo todo.
En este caso es razonable agarrar mi control de favoritos, el de mosaicos y el de pendientes, y meterlo en un archivo. De tres chunks hice uno más grande. Si los productos originales son de Gemini, él es mejor; si no, Claude. Nota: tienes que tener un estimado de líneas, porque si no Copilot o Gemini hacen tal reingeniería que te borran lo que ya funcionaba. Y ya que tienes lo bueno, respáldalo. Por eso trabajé ciertas cosas en repositorio de Rocky Linux. Lo jalo directo y lo pruebo.
Otro caso:
En EVE Online hice una lista de pilotos, en mosaicos, ordenados por número de naves que tienen. No es fácil, pero si no luego me hago un lío. Módulo CREW / ASSETS, porque veo a los pilotos y cuántas naves tienen. Luego le pedí a Gemini hacer una versión que me dijera otros datos, de pilotos de menos de 6 millones de puntos pero con filtros. Módulo Control de Alphas (término de EVE).
Así que me encuentro con dos aplicaciones muy similares, hechas por mí con ajustes de Gemini, y le pedí a Claude que las juntara. ¿Resultado? 450 + 420 líneas = 730 por optimización.
Sí. Todavía cabe algo menor. A veces Claude suma líneas.
Como dato, ese script tuvo dos errores, pero con diez líneas de código a mano quedó (diferentes filtros por tab vivo).
- tip: Te sugiero probar primero a fusionar con Gemini y luego con Claude, pero prueba bien
Voy a mostrarte unas pantallas de mi sistema de mosaicos de cosas que estoy revisando. Asumimos que el archivo actual es de 138 líneas. Y fíjate qué interfaz más limpia. Un click derecho lo abre en una nueva ventana.
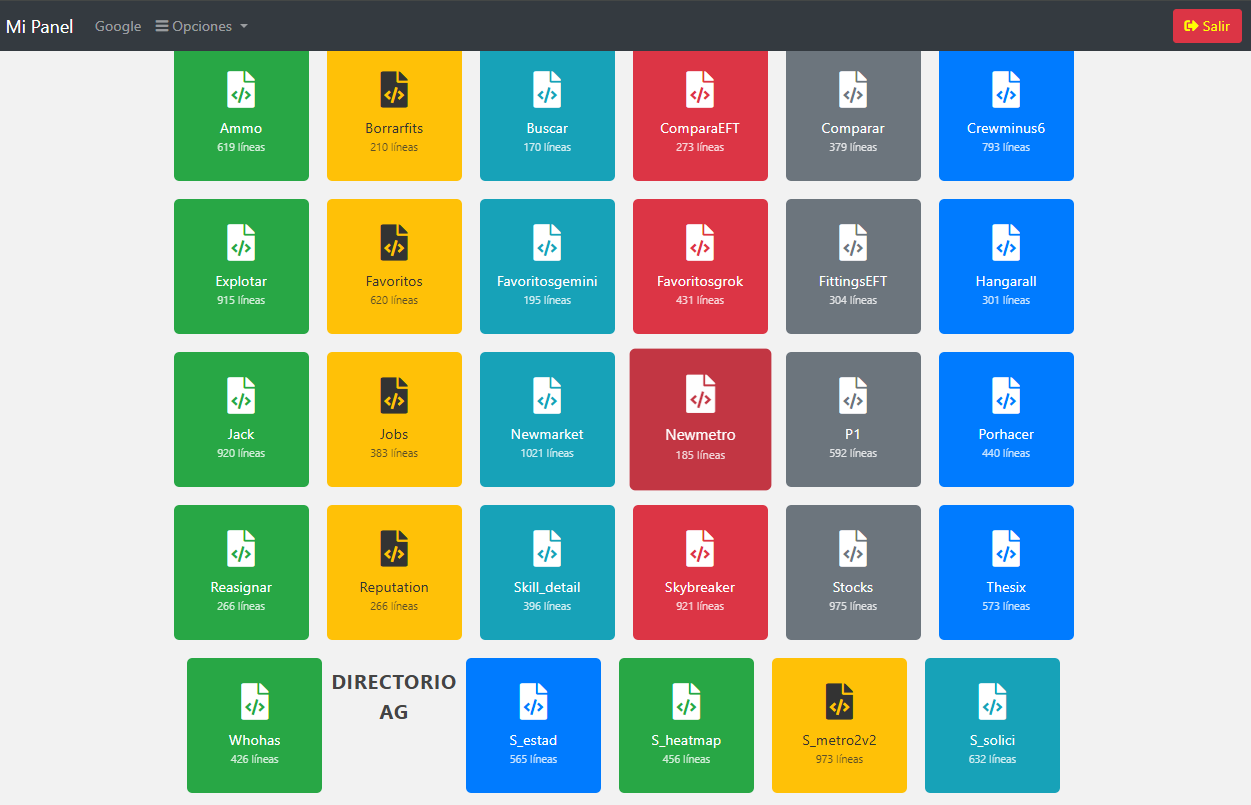
Como ves, es muy limpio y además el cuadro blanco de directorio me dice lo que hay en un directorio. Es tan fácil como poner una línea que pase el parámetro de directorio.
Pero esto no lo puedes hacer con Node, Quarkus, React o lenguajes pesados, que además debes compilar. Python y PHP son los mejores para esto y por simplicidad Php y Go le ganan a Python
Skybreaker es un módulo de control para enfrentamientos abisales de PVE, similar a los runs de abyssaltracker.com, pero en 931 líneas de código. Se hizo juntando cinco chunks. El enemigo final es Skybreaker en Tier Cero, de ahí el nombre. Newmarket lleva un sistema de jalar las órdenes de compra del juego y control de contratos. Hace como diez cosas y quedó de 1021 líneas. Jack es una mezcla de scripts para hacer evaluación de personaje como hacía hace años Jack of Knife, y para mil líneas no está mal. Stocks es un archivo muy raro.
- Básicamente, un control de cuánto dinero tengo de ciertos asuntos que antes llevaba en Excel. Lo puedo modificar después para control de gastos, pero hace mucho más de lo que parece e igualmente es completo. Gracias a el puedo trabajar sin excel en lo que controlo.
Pero fíjate en la siguiente imagen:
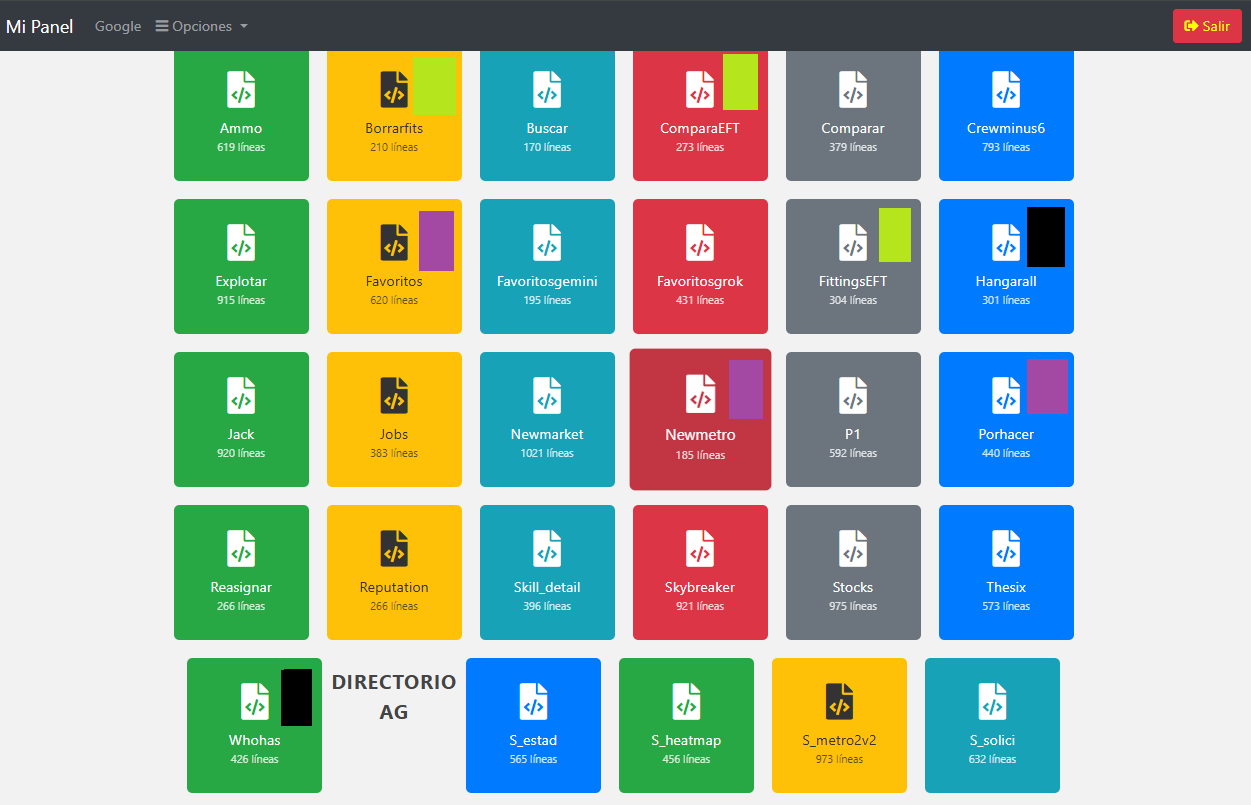
En esta segunda imagen puse cuadros de colores. WhoHas y HangarAll están probados, son de un control específico de inventarios (cuando tienes muchas sucursales o, en este caso, pilotos). Te dejan buscar quién lo tiene y qué es lo que necesitas. Sin embargo, hay detalles que puedo mejorar, y prefiero esta cercanía de las mil líneas para fusionar (cuadro negro).
Fittings EFT + Compara EFT + Borrarfits pueden unirse en uno solo, en cuanto refine la idea (cuadro verde). Por ejemplo, el Crewminus6 de arriba es un ejemplo de dos scripts fusionados.
El color morado suma Newmetro, el que me hace estos mosaicos, con Favoritos y Porhacer. 440 + 630 + 185 líneas creo que es manejable, y lo trataré de automatizar con Claude y con Gemini.
Bastante simple, ¿no?
Con el concepto de chunks tienes una interfaz visual útil de inmediato. Y esto lo haría en un Rocky Linux, no en un servidor del trabajo donde debo hacer cosas mucho más pesadas.
En resumen:
Para estar Domando la caja negra, y trabajar con IA requieres modelos mentales claros, métricas prácticas (líneas de código) y organización visual (mosaicos).
Son modelos mentales. Y todo parte de la idea del límite práctico de 1000 líneas de input y 1200 de output antes de que se Alucinen. Si tienes respaldos es controlable. Las LOCs o líneas de código me permiten darme una idea de qué está pasando.
Un modelo mental es estrategia mental para no volverse loco gestionando múltiples entornos.